Glenn Engstrand
Once exclusively in the province of academia, Machine Learning is now rapidly getting adopted by many organizations large and small and used with various degrees of effectiveness. Currently there is a plethora of active open source projects, libraries, technologies available for you to do ML. Which one should you choose?
For the most popular use cases where AI is used to shape online behavior based on offline training, current consensus wisdom says that scikit-learn is your best choice. For use cases where training must occur on big data, then consider either Tensorflow or Spark MLlib.
What I wanted to discover was which ML library would be the best in helping me analyze the performance data I collected when I ran load tests on six microservices in both Amazon’s and Google’s clouds. What I did was analyze the data using the decision tree algorithm in the following four technologies; Spark MLlib, scikit-learn, KNIME, and Weka. In order to do that, it was an important requirement that I could study the models that the machine would learn. But first, let’s talk about the libraries that did not get fully evaluated.
Why not Tensorflow, you ask? Tensorflow is a very popular dataflow programming python library most known for its deep learning neural network algorithms. While it does have a random forest algorithm, it does not have a decision tree algorithm. I was hoping to use a single tree random forest approach that is similar to what Spark MLlib does. While there are plenty of ways to inspect the model of the Tensorflow job itself, I could not find an easy way to output the decision tree model for inspection. I will include coverage of Tensorflow where I can.
There is a programming language, simply called R, which is very popular for statistical computing. The R environment includes a function for building decision trees called ctree. The ctree function uses CI, or Conditional Inference, trees which is a regression algorithm that uses recursive binary partitioning and permutation based significance. This algorithm is not really appropriate for our use cases because our outcomes are discrete. There is another function called rpart but I never got it to work properly.
I first learned about the Apache Mahout project about a decade ago. Back then, it was all about running collaborative filtering, clustering, and classification algorithms on Hadoop for big data oriented ML. Since then, it has pivoted into a distributed linear algebra framework by which you can write your own algorithms. Instead of Hadoop, it integrates with Spark. The source code still has a random forest class but it is deprecated and still depends on Hadoop. I decided to pass on that.
Before we can evaluate how well these projects can help us analyze microservice performance, we must first understand how each project differs in the decision tree algorithm that they employ. I have already covered the basic decision tree algorithm in my last blog on Analyzing MSA Performance with ML. The most popular variations are the CART and C4.5 algorithms.
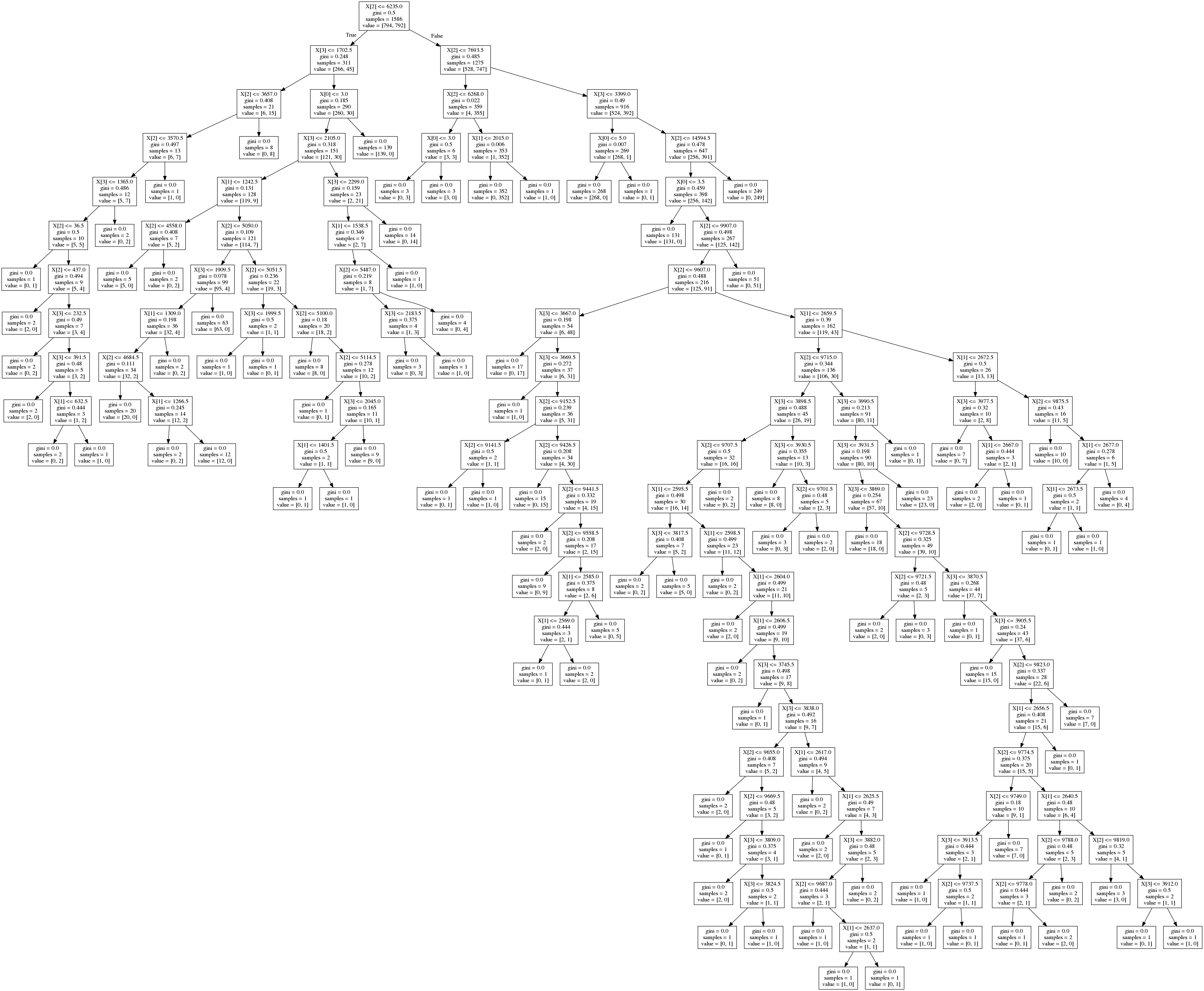
CART stands for Classification and Regression Trees. The two most popular CART implementations of the splitting criterion (see my last blog) are based on the information gain entropy and the Gini impurity. The projects evaluated here that use CART are scikit-learn and Spark MLlib and they both can be configured to use either. Gini impurity is about the measure of the homogeneity of the labels at the node. The lower the number, the better. Zero means a unanimous population. Entropy is the difference between the parent node impurity and the weighted sum of the two child node impurities. The quality of the resulting models are very similar. Most people choose Gini impurity because it takes less computation time. CART uses cost complexity pruning which is a post pruning algorithm. Sum up all the misclassification errors for every leaf in the subtree. Add to that the product of the regularization parameter and the number of leaf nodes in the subree. If the result exceeds a threshold value, then the node gets pruned.
Both Weka and KNIME use the C4.5 algorithm which has available two algorithms for the splitting criterion, gain ratio and gini index. With the gain ratio, those tuples that more evenly split the population are favored due to their higher normalized information gain. The gini index here is very similar to the gini impurity splitting criterion from the CART algorithm. The two most popular implementations of the stopping criterion are EBP and MDL. MDL, or Minimum Description Length, comes from information theory. It seeks a model within a class which permits the shortest encoding of the class sequence in the training sample, given the features. There is a trade off between the size of the subtree and the number of training errors. KNIME uses MDL. EBP, or Error Based Pruning, considers the errors among the training examples at a leaf of the subtree to give an estimate of the error probability for that node. Weka can be configured to use either EBP or MDL.
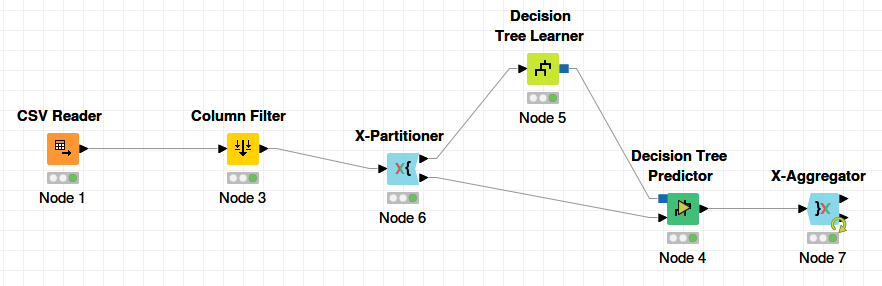
Let’s talk about the User eXperience for these technologies. Both Weka and KNIME support a Graphical User Interface which does not require you to write any code. They both let you visualize the data with a scatter matrix. The GUI for Weka is, ahem, shall we say quaint and leave it at that but it does get the job done. The only part of Weka that I could figure out was the explorer and workbench sections which look the same to me. Though very retro, one nice feature of the Weka GUI was that it was very easy to explore a wide variety of algorithms with your data. I used J48 for the cloud outcome and REPTree for the feed outcome. The GUI for KNIME is very workflow oriented where you drag and drop various IO, manipulation, and analytics nodes then connect them up for a graphical representation of the data flow. I used the CSV reader to import the file, the column filter to remove the unwanted time based columns, the decision tree learner to build the model, and the decision tree to image node to display the model and save it as an image file. KNIME is an Eclipse plugin which means that there will be a lot of familiarity for those who already use the Eclipse IDE.
Both scikit-learn and Spark MLlib are for developers where writing code is necessary. The scikit-learn library is for python programmers and the Spark MLlib is for scala developers (although it also comes with python bindings). I just used a text editor and the command line. Data scientists prefer running these kind of jobs in a Jupyter notebook which is well known for its ability to create and share documents that contain live code, equations, visualizations and narrative text. I had no trouble running the Tensorflow and scikit-learn programs from the Anaconda distribution of Jupyter. There is one caveat with Tensorflow and Jupyter. Any mistake in your code will crash the Python process which means you won’t see any diagnostic messages in Jupyter. I had to run the Tensorflow programs from the shell in order to debug them. The logic for writing these kind of ML programs is very similar. You import the CSV file into two internal data structures, one for the outcome and the other holds the features. All feature data must be numeric. Outcomes must be numeric with Spark MLlib and integers with Tensorflow whereas scikit-learn is a lot more flexible with the data types of outcomes. You create a decision tree object with various configuration properties. You train or fit the tree model to the data. Finally, you output / render the model for subsequent inspection.
How do these various technologies differ when it comes to inspecting the decision tree model itself? KNIME allows you to view and save a graphical representation of the tree to a PNG file directly from within its desktop application. There is a bug in the KNIME GUI where the image file clips the model slightly. There is also not one but two pretty cool interactive model explorers. With Weka, you can open a window with a visualization of the tree that you can then print screen and capture in a PNG file. With scikit-learn, you can save the model as a PDF and to a text file in graph description language that can be rendered to a PNG with the graphviz tool. Spark MLlib presents only a text representation of the model.
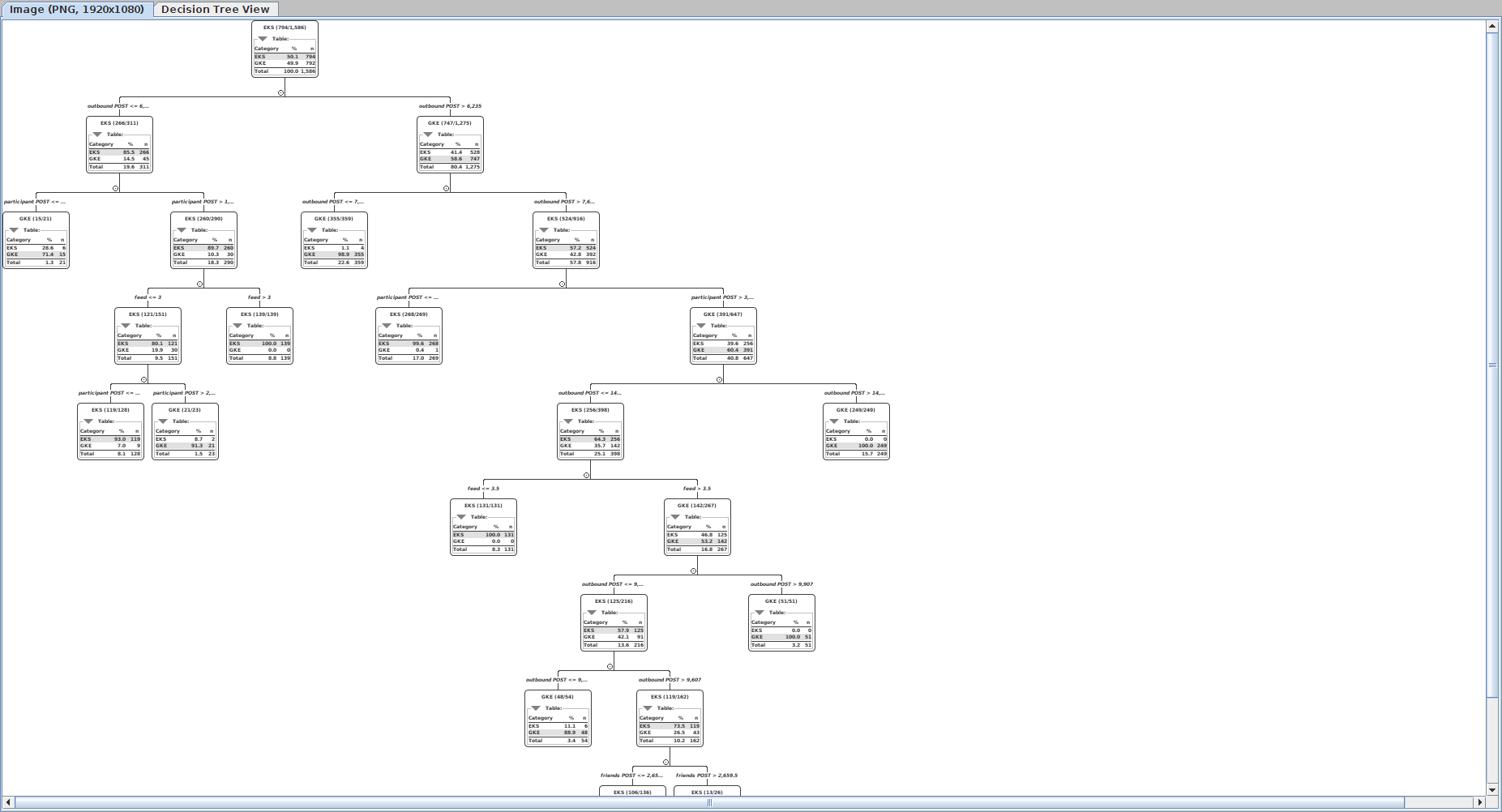
The decision trees for Spark MLlib and scikit-learn are a little harder to understand because everything is a number with those libraries. There are no labels. You have to figure out that X[2] is for the outbound post throughput metric because that is how the code loaded the contents of the CSV file into the features array. The decision tree can display metrics with each node that helps you understand the quality of the decision that the node represents. With Weka, what you see is the breakdown of counts of data points in the partition that both meets and does not meet the threshold criteria. With KNIME, you get to see both percentage and counts. With scikit-learn, you see the Gini impurity index, the total number of samples, and the counts. There is no display of node quality with the text only representation of the Spark MLlib tree.
In the last blog, I covered the ML pipeline where you split the data up into training and testing data. You can gain a measure of prediction accuracy by comparing the predicted outcomes from the testing data on the model trained on the training data with the actual outcomes. Here are the results from the testing phase regarding accuracy when predicting cloud vendor based on throughput data. KNIME and Weka use the k-fold cross validation algorithm for splitting up the data into training and testing data while the other libraries used a simple 60 / 40 split.
| library | accuracy |
|---|---|
| KNIME | 94.70% |
| Weka | 94.26% |
| scikit-learn | 93.70% |
| Spark MLlib | 91.77% |
| Tensorflow | 91.50% |
All things considered, what are my findings with these libraries? In the category of model inspection and interaction, KNIME is the best. When it comes to the splitting criterion, Weka, KNIME, and scikit-learn are all tied for the lead and Spark MLlib came in last. When it comes to the stopping criterion, Weka is the best and scikit-learn is the worst.